8. Open Finnish two-level morphological analyser¶
This article describes a plan and a project OFITWOL to build an open source two-level morphological analyzer for Finnish as it is described in Nykysuomen Sanakirja [NS]. It is the first full-scale implementation of the principles of the Simplified Two-level Model as described in Morphophonemic representations. The morphophonemic representations in the lexicon entries was deduced semi-automatically out of model words by aligning stem allomorphs and affix allomorphs. In this way, a fairly large number of two-level rules were written in a semi-automatic manner but, in return, the lexicon was greatly simplified and generalised. Instead of a huge number of inflectional classes, the OFITWOL has only one class for nouns and another for verbs. Rules take care of all variation within the stems and among allomorphs of endings.
OFITWOL has several functions and components, including:
An analyser FST
ofitwol.ofstwhich takes a word form as input and produces the base form and morphological features of the underlying lexeme(s) according to the vocabulary in the lexicon. This analyser has some variants, includingofimphon.ofstwhich produces the morphophonemic representation of the base form instead of the conventional base form, andofientry.ofstwhich produces an entry that would generate the surface form (and this might be useful in collecting attested compounds for an enlarged lexicon).A guesser FST
ofiguess.ofstwhich also takes a word form as input and produces a set of possible lexicon entries or base-forms (and optionally also inflectional features). When applied to a corpus, it would provide sets of candidates for new lexemes found in the corpus.Tools using the guesser FST for deducing further lexeme entries interactively or from sets of word. One tool lets the user to give an inflected form for which the tool responds with a set of principal forms for each guessed lexeme entry. Another tool utilises a word list from a corpus for selecting the most likely lexeme entry for a given word. Yet another tool works on its own and produces a list of good candidates of lexeme entries out of it.
The document first describes the current implementation of OFITWOL. In the last section, some information is given on the background and some further details of the steps and stages of building the analyser and a more detailed comparison between this and some other analysers.
8.1. How the rules work in OFITWOL¶
The lexicon simply lists the morphophonemic representations of the lexemes and affixes and defines their acceptable combinations. In brief, the lexicon defines the acceptable sequences of phonemes and morphophonemes. The lexicon OFITWOL does not define base forms for lexemes separately for each lexeme, as they can be mechanically derived from the morphophonemic representations. The overall structure can be represented as a set of six representations which are tied to each other via rules or other relations (which are, of course, composed into a single transducer). The example word form is saappaassa, ‘in a boot’:
The underlying representation of the word form consists of the base form of the lexeme and the grammatical tags describing the part of speech and the number and case of the surface word, e.g. the sequence of the following nine symbols:
s a a p a s +N +SG +INE
The second representation differs from the first by having some zero symbols (Ø) freely inserted in the base form part. In the shown below, ther is only one shown where the zero is where it will be needed:
s a a p Ø a s +N +SG +INE
The third representation is the morphophonemic representation of the stem of the base form of the lexeme and it still has the part of speech and inflectional features in the end of the string. This representation is in the lexicon. The lexicon allows noun stems to be at the beginning, and noun endings to follow. The two-level rules map the third representation into the second representation:
s a a p {pØ} a {sØh} {aäØ} +N +SG +INE
The fourth representation has the same morphophonemic representation of the stem of the lexeme, but here the endings are in their morphophonemic form. The lexicon entries of the endings relate the features of the forms with the morphophonemic forms of the endings, thus the lexicon maps
+N +SG +INEintos s {aä}:s a a p {pØ} a {sØh} {aäØ} s s {aä}
The fifth representation is what the two-level rules map out of the fourth representation. Thus,
{pØ}is mapped toØ,{aäØ}toaetc. At this stage, as in representation 2, the zeros are (auxiliary) symbols, not empty strings:s a a p p a Ø a s s a
The sixthe representation is the actual surface form as it is written. It can be reached from the previous one by deleting the zero symbols (
Ø):s a a p p a a s s a
Representations 4 and 5 are related to each other by two-level rules which neither delete nor insert any symbols. Similarly, representations 2 and 3 are related to each other by the two-level rules, but with minor differences. The relation between representations 4 and 5 often permits some free variation in the inflected word form whereas the relation between 2 and 3 is expected to permit only the standard or canonical base form. See a separate discussion below.
The representstions 3 and 4 are related to each other by a LEXC lexicon. Stem parts and the ending parts are mapped in a different manner. The stems are in their morphophonemic representations and in the lexicon the two representations of the stems are identical. Lexicon entries for lexemes are thus quite minimalistic, e.g. like the following:
saap{pØ}a{sØh}{aäØ} /s;
No explicit base form is given here, but it can be generated by using the rule transducers in the reverse direction.
The LEXC entries for affixes relate the features (e.g. +SG +INE) on level 3 with the morphophonemic representations of the endings (s s {aä}) on level 4. The entry in the LEXC lexicon would be e.g.:
+SG+INE:ss{aä} Poss;
The last LEXC sublexicon (e.g. /v) before the affixes inserts the morphophonemic representation of the ending that is required in the base form and the part of speech feature, in this case, the first infinitive for verbs (e.g. {dlnrtØ}{aä}+V:). The LEXC lexicon of affixes thus enters or deletes symbols, as opposed to the two-leve rules which are length-preserving.
Levels 1 and 2 are related by a trivial FST which freely inserts zero symbols, and the levels 5 and 6 by a trivial FST which deletes all zero symbols. Note that levels 3 and 4 do not contain any zero symbols, neither do levels 1 nor 6. Levels 2 and 3 have the same number of symbols, and so do the levels 4 and 5.
Here is an example of the six levels for a verb:
1: h a k a t a +V +PAST +ACT +3SG
2: h a k Ø a Ø Ø t a +V +PAST +ACT +3SG
3: h a k {kØ} a {ØsnØtt} {aØØØØ} {dlnrtØ} {aä} +V +PAST +ACT +3SG
4: h a k {kØ} a {ØsnØtt} {aØØØØ} {i} {VØ}
5: h a k k a s Ø i Ø
6: h a k k a s i
The relations between these representations are all FSTs, and in the actual analyser, they have been composed and inverted, so the analyser consists of just one FST ofitwol.ofst which takes the written word form as input and produces the base form and morphophonological features as output.
8.2. The set of example words¶
The new rule compiler for Simplified Two-level Model is based on examples. No rules can and should not be written until one has a comprehensive set of example words. The example words combine the information on the levels 4 and 5 in the above framework. They are expressed by using pair symbols. Examples could thus be e.g.:
k a u p {pØ}:Ø {ao}:a s s {aä}:a
h a k {kØ}:k a {ØsnØtt}:s {aØØØØ}:Ø {i}:i {VØ}:Ø
First, a table was made where there was a row for each relevant model word and a column for each relevant inflectional form. A separate table kskv-table.csv was made for 68 verbs and another kskn-table.csv which covered 98 nominals (nouns or adjectives). One or a few lexemes were chosen from each inflectinal class so that lexemes with and without consonant gradation were covered as well as words conforming to back and front vowel harmony. The table was then converted into the initial set of some 1900 examples using the relevant programs (twol-table2words, twol-words2zerofilled, twol-zerofilled2raw and twol-raw2named) in the Python 3 package twol. The initial set of examples was slightly extended as some more words and inflectional forms were included. The current file contains less than 2400 examples (See ofi-examples.pstr).
8.3. Two-level rules¶
Some 200 mostly quite simple two-level rules were written by using the examples, see Simplified two-level model for the general principle and Rule formalism for details of the rule formalism. Each rule was was added to the two-level grammar separately and immediately tested against the set of examples.
8.3.2. The two-level rule grammar¶
The whole rule set consist of eleven groups:
- definitions.twol
Common definitions that are used in all rule groups.
- consonants.twol
Rules for consonant gradation and other alternations which may occur both in nominals and verbs.
- vowels.twol
Vowel lengthenings and shortenings common to nominals and verbs.
- nounfinal.twol
Alternations of stem final vowels in nominals.
- nouninternal.twol
Rules for various consonant alternations in nominal stems.
- nounendings.twol
Rules which control the shapes of some endings and the types of nominal stems with which they may be combined.
- verbfinal.twol
Alternations of stem final vowels in verbs.
- verbinternal.twol
Alternations of stem internal consonants in verbs.
- verbsuff.twol
Rules for producing the correct shapes of verb endings.
- rules-variation.twol
Rules which control alternative forms which are accepted as input but which are not desired to be present in the output base forms of the analyzer which produces the base forms.
- rules-normalize.twol
A few rules needed for generating the base forms
The nine first groups the rules that are common to both relations in the configuration discussed above, ofi-rules.twol, the extra rule for the relation between the levels 4 and 5 ofi-rules-extra-in.twol and the extra rule in the relation between the levels 2 and 3 ofi-rules-extra-out.
8.4. Managing variant forms¶
EMSF allows more morphophonemic variation than the present day Finnish, e.g.:
onneto<i>nin addition to the standard formonneto<>n(‘unhappy’, adjective, nominative, singular)korke<e>in addition tokorke<a>(‘high’, adjective, nominative, singular)kih<aja>ain addition tokih<ise>e(‘to hiss’, verb, active, present tense, 3rd person)vene<h>essäin addition tovene<>essä(‘in a boat’); in MSF the noun has stemsvene,veneeandvenet, but in EMSF there are two additional stemsveneheandveneh. A morphophoneme{Øth}easily describes this variation in EMSF, but the correspondence{Øth}:hmust not be present in the normalised base formvene.
The two first examples are solved through the morphophonemes that describe the variation and the third type is solved by includin some morphemes in the lexicon. The former type needs special attention, because otherwise the rules will generate several base forms for words containing such morphophonemes.
8.4.1. Allowing variation¶
When there is no variation, one may often use the double-arrow two-level rules such as {ao}:o <=> _ {ij}:. Then, the morphophoneme input symbol has only one possible output character (or zero). There are two ways to allow several alternatives: Firstly, one may give the alternatives in the left-hand side of the rule, e.g. {aØo}:Ø | {aØo}:o <=> _ {ij}:. Such a rule clearly allows both Ø and o as the output characters for the input symbol {aØo}. It would be no problem if the lexicon would consist of explicit base forms given to each lexicon entry. In OMORFI we avoid this base-forms by generating the base-forms automatically from the morphophonemic representations. The other method of allowing variation is to use combinations of right-arrow rules => and exclusion rules /<= and separate the examples and the rules for the variants from the standard rules.
The file containing the examples must, thus, be split in two parts. The main part contains all examples where the relation reflects the standard output forms and another which contains only the variant forms. The variant forms, thus, have the surface representation of the non-standard form but their morphophonemic representation is the same as in the standard forms. The combination of these two sets of examples is the effective test for input two-level rules and the standard part alone is the test set for the output rules which generate the base forms.
8.5. Affixes¶
All information about inflectional affixes and their combinationss is strored in one CSV file with some 170 rows: ofi-affixes.csv. For each affix, this file contains some columns which is needed for building a LEXC format lexicon out of the affix entry.
- ID
The name of the LEXC sublexicon to which the affix belongs.
- NEXT
The name(s) of the LEXC sublexicon(s) whose affixes or entries may follow this affix.
- MPHON
The morphophonemic representation of the affix as it appears on the level 4 of the overall structure.
- BASE
For inflectional affixes, this field is empty, as such affixes are not part of the base form. For derivational endings, the this field repeats the contents of the MPHON field in order to output the base form of the derived lexeme (and not that of the root lexeme). Some sublexicons whose ID starts with a slash “/” are a bit special. In order to make the guesser output complete entries, there special sublexicon names is added to the LEXC when the table is converted for guessing.
- FEAT
Morphological features which describe the part of speech or inflectional form associated with the affix. The feature names are there without the preceding plus “+” sign which is added during the conversion. Practically all inflectional features are given in this file and in this column, so one may easily change the feature names as needed.
- WEIGHT
A possibility to set a weight for infrequent forms and especially for dynamically constructed compound words.
- MODE
Some rows in the table are not relevant both for normal analysis and for guessing. This field can be used for excluding or including some rows. In addition to these two major modes, there is a mode
Bwhere lexeme entries are expected to have an explicit base form in addition to the morphophonemic form.
There is a Python 3 script affixes2lexc.py which converts this table into a LEXC lexicon file according to the mode.
8.6. Lexeme lexicons¶
In addition to the affixes, the lexicon contains a few lexeme lexicons where the lexemes are given in a format similar to the LEXC format, except that the morphophonemes (and possible feature names) are not explicitly listed as Multichar_Symbols. These files with a suffix entries are converted into the LEXC format using a Python 3 script entries2lexc.py.
lexic-s.entries contains the morphophonological stems of some 35,000 nouns (‘substantiivi’), e.g.:
votjak{kØ}{iieØ} /s votkale{Øth}{ØeØeØ} /s votk{aØ} /s
lexic-a.entries contains the morphophonological stems of some 11,700 adjectives, e.g.:
autua{sØh}{aäØ} /a auvois{aØ} /a auvoi{ns}{eeØØ}{nØØØ} /a
lexic-v.entries contains the morphophonological stems of some 15,900 verbs, e.g.:
kaupunkilaistu /v kaupunkilaist{aØaae} /v kaupustel{eØØØei} /v
lexic-p.entries which contains entries of adverbs, conjunctions and othe particles, a total of some 8,700 entries, e.g.:
pullolle /ps pulskasti /pc pum /p
lexic-r.entries contains (an incomplete) selection of pronouns most of which are somewhat irregular, total some 800 lines, e.g.:
eräs:erä{sØh}{ØäØØØ} /r joku+PRON:joku joku+PRON:jonkun joku+PRON:jonakuna joku+PRON:jotakuta
lexic-n.entries contains an (incomplete) selection of common numerals, only some 100 lines e.g.:
kaksitoista+NUM:kahtatoista Clit kaksitoista+NUM:kahteentoista Clit puolitoista+NUM:puolitoista Clit sadas:sada{ØnØnn}{snt}{ØeØØØ} /n sata:sa{td}{ao} /n
lexic-special.entries contains a collection of some 2000 mostly noun entries which need some special treatment to avoid extra compound analyses. The entries in this lexicon are not allowed occur as a second part in a compound, and thus the possible or common compounds are also listed here, e.g.:
i{kØ}{äØ} /s aikuis_i{kØ}{äØ} /s aloitus_i{kØ}{äØ} /s elin_i{kØ}{äØ} /s
8.7. Linkages between sublexicons¶
The following graph summarises the connections between the sublexicons. Possible sequences start from the Root sublexicon which only contains links to the sublexicons which contain the stems of nouns, verbs etc.
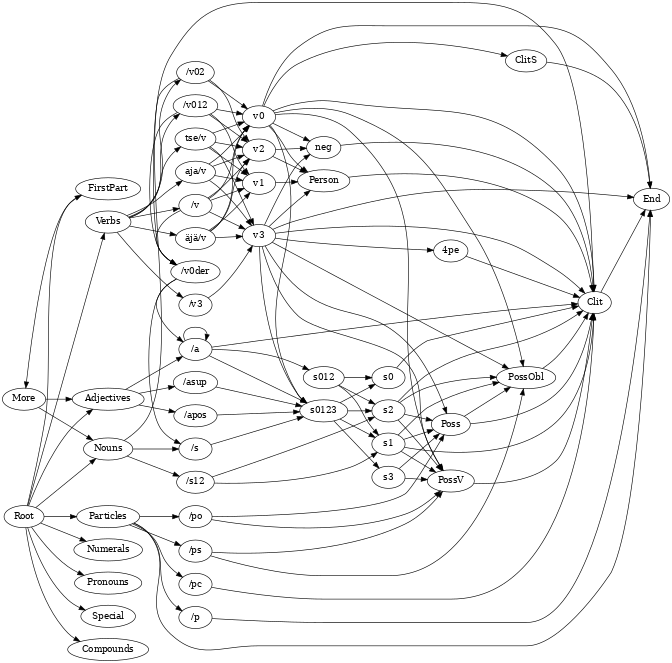
The graph was created automatically from the LEXC lexicons that are the building blocks of the analyser. A Python 3 program, twol-lexc2dot which reads through a set of LEXC lexicons and produces a graphviz dot graph where the sublexicons are represented as nodes and the continuations as edges or arrows between the nodes. The above graph was made by:
cat root-mphon.lexc lexic-firstpart.lexc lexic-s.lexc lexic-s.lexc \
lexic-a.lexc lexic-v.lexc lexic-p.lexc endings.lexc |
twol-lexc2dot -e -s "/" > ofilexicon.dot
8.8. Miscellanious Notes¶
8.8.1. Other morphological analysers of Finnish¶
OFITWOL is not the first or only morphological analyser for Finnish. On the contrary, during the past decades, several morphological analyzers have been built for Finnish, including at least:
FINTWOL, original version described in [koskenniemi1983]. It was later developed into a commercial product by Lingsoft
MORFO developed by Kielikone (Jäppinen, H., Nelimarkka, E., Lehtola, A. and Ylilammi, M.: Knowledge engineering approach to morphological analysis. Proc. of the First Conference of the European Chapter of ACL, Pisa, 1983, 49–51.)
Ment Model by Olli Blåberg (Blåberg, Olli: The ment model - complex states in finite state morphology. Institutionen för lingvistik, Uppsala universitet.) and later on adapted by Xerox into the XFST framework
OMORFI by Tommi Pirinen using the HFST tools, see e.g. Omorfi—Free and open source morphological lexical database for Finnish
Voikko based on the Malaga platform implemented by Björn Beutel.
8.8.2. Goals set for OFITWOL¶
At the time when this project started around 2017, the goals for OFITWOL were:
The building of OFITWOL was meant to demonstrate the application of the simplified two-level model into building a full-scale morphological analyzer in order to validate the principles and methods and to make it easier for other projects to learn from the expriences of this project. (The methods of simplified two-level model were followed and the extensive project appears to prove the feasibility of the method.)
The aim was to make OFITWOL flexible enough to be adapted for various purposes including the analysis of literary and newspaper texts from the 19th and 20th centuries, using it in the description of Finnsh dialects and in the comparison of Modern standard Finnish with those, Old Literary Finnish and with languages closely related to Finnish. (It appears to be straightforward to add dialectal ending allomorphs. Just a minor change in one rule would allow consonant gradation
t~Øas in Kalevala and some dialects.)OFITWOL aimed to be descriptive and permissive rather than normative. The normative approach has been the guideline for describing the inflection in more recent dictionaries such as Kielitoimiston sanakirja or its predecessor Suomen kielen perussanakirja. In particular, OFITWOL was intended to accept also inflectional word forms which were used in the 19th and 20th centuries but which are rarely used any more. Most other Finnish morphological analyzers are more or less normative and try to allow only those forms which sound unmarked today. (The inflectional paradigms are rather permissive and in some details even more permissive than NS.)
Adopt and develop disciplined methods for creating lexical entries mechanically from word-lists such as Nykysyomen sanalista, manually using interactive toolst or semi-automatically using data from large corpora.
Document the various components well enough so that other scholars can understand how it is built and how it can be modified and improved, and more importantly attract further scholars to improve and develop OFITWOL. As much as possible, the steps and components ought to be documented prior to their building or at least simultaneusly with the implementing.
Make all rules, lexicons, scripts, programs and documentation freely available and extensible so that they can be used by anybody for any purpose and modified as desired. (Now available in Github under GPL 3 license.)
8.8.3. Language resources that were available¶
Helsinki Finite-State Transducer Tools (HFST) for building the further tools needed at various stages of the project. The finite-state tools are heavily used both as command line programs and as embedded in Python 3 in all stages of the work.
The tables for inflected word forms for paradigms given in Nykysuomen sanakirja [NS] and in Suomen kielen käänteissanakirja [KSK] which reflect the same sets of defined inflection classes. These two are used as a primary authority when determining the morphophonemic alternations in lexical entries.
Word list from the KSK which lists the non-compound headwords in NS and their part of speech and inflection class. This list was extensively used in verifying the hand-compiled regular expression patterns which describe possible shapes of words in relation to their inflection. The word lists themselves were temporarily converted and used as a lexicon to find a selection of relevant lexemes by analysing word lists from large text corpora. The original KSK word list or its direct derivatives were not included in the OFITWOL. Instead, only output of analyses were used versions what are called OFITWOL and are now freely available.
An earlier version of nominal and verbal affixes as a CSV table written by the author and which was used in some attempts to convert NSSL into an analyser. It was used as a starting point for producing the ofi-affixes.csv.
Suomen kielen tekstipankki, which is a collection of several million words of Finnish texts and is stored in the Kielipankki. The texts themselves were not included in the results but they may be used as a primary resouce of occurrences of word forms and thus for determining the inflectional properties of tentative lexical entries.
An extensive list of word forms (KLK) from low quality OCR of huge amounts of Finnish texts from the 19th and 20th centuries. This material was one of the primary corpora used because it also containde older words and word forms. (National Library of Finland (Kansalliskirjasto) (2014). The Finnish N-grams 1820-2000 of the Newspaper and Periodical Corpus of the National Library of Finland [text corpus]. Kielipankki. Retrieved from http://urn.fi/urn:nbn:fi:lb-2014073038)
Nykysuomen sanalista [NSSL] which is a word list with inflectional coded and can be used under the LGPL license. The inflection codes in NSSL are those used in Kielitoimiston sanakirja. Word lists in OMORFI and Voikko were also available but these and the NSSL list was not used in building OFITWOL. Their lexical material could easily be incorporated later on.
8.8.4. Overview of the stages¶
Completing the paradigm tables and sets of word form examples. Word forms in the tables are segmented so that morphs are separated from each other by a boundary. Establishing the morphophonemes through alignment as is explained in Morphophonemic representations. This is done separately for nouns, (adjectives) and for verbs. The result of this stage is a collection of examples as space-separated pair symbol strings. The result is free. (Done for verbs and nouns by March 2019.)
Writing and testing the two-level rules as is explained in Discovering raw two-level rules, Rule formalism and Compiling and testing the rules. The result of this stage is a two-level grammar which covers all relevant phoneme alternations of the language as they are present in the examples. The result is free. The tuning of the rules might result in some revisions in the sets of examples (such as correcting mistakes in the examples and adding missing examples). (Done for verbs and nouns by March 2019.)
Writing and testing regular expression patterns for NS/KSK inflection types as described in Guessing lexicon entries. The patterns can be tested against the KSK word list by converting the word list into a LEXC lexicon. A script checks whether it covers the KSK vocabulary and reports items not covered. The patterns are used for determining the underlying lexicon entry from a set of word forms. The patterns may be complete in the above sense but still too permissive which results in too many possible lexical entries for sets of inflected word forms. The patterns need to be made strict enough to exclude most of the extra entries. This is achieved by making the patterns reflect the phonological patterns present in inflection classes. The result of this stage is a set of patterns which can be used both for converting the KSK word list into a LEXC lexicon and for guessing lexicon entries from scratch or with the aid of a corpus. The result is free.
Build a LEXC lexicon out of the verb, noun and adjective entries of KSK which together with the two-level rules is a morphological analyzer for Finnish. The result of this stage is a CSV list giving each KSK verb, noun and adjective, a two-level lexicon entry using morphophonemes associated with its base form and inflection code in KSK. This result cannot be published as such, but it can be used for processing further results. From this CSV file, the affixes and the two-level rules one produces a KSK morphological ananlyzator KSKTWOL1 in a straight-forward manner, and this is also project internal. Note that KSKTWOL1 is not prepared to analyze compound words.
Use KSKTWOL1 against various corpora including SKTP and KLK, in order to collect sets of (non-compound) lexeme entries which occur in them. The restriction of KSKTWOL to such a subset is taken and closed class entries (pronouns, conjunctions, numerals) are added manuals. The results are of type OFITWOL1. These are free lexicons (a seprarate one for each corpus) which can be published and combined according to needs.
Augment OFITWOL1 with a mechanism for compounding (two part compounds) resulting in OFITWOL2 (which is again free). OFITWOL2 is used for collecting tentative sets of compound entries from corpora. Compound words with a sufficient frequency are (after at least superficial human checking) added to the lexicon resulting in OFITWOL3 (which is free).
One can guess more entries by using the patterns as an entry guesser which uses a word form list out of a corpus. This time it would be useful to use a word form list from which all word forms recognized by OFITWOL2 or OFITWOL3 have been removed.
8.8.5. Alignment, morphophonemes and rules¶
The tables for example words and their inflectional forms were taken from the Reverse Dictionary of Modern Standard Finnish [KSK]. The parenthetical forms were reproduced with their parentheses. The parentheses were ignored in the processing, so less common forms became equally acceptable as the recommended forms in agreement of the goals of OFITWOL. Some additional inflectional forms were included (and enclosed in square brackets [...]) according the judgement of the author. A few inflectional classes were considered to include suppletive segments rather than just phonemic alternations, such as nouns like askel and askele or korkea and korkee, and verb forms like haravoin and haravoitsen. Such classes were simplified by splitting them into two subclasses anticipating the representation of such lexemes with two entries in the final lexicon. Entries for pronouns, adjectives and conjunctions were not included in the process. They were marked with a question mark (?) in the first column. The tables are in kskn-table.csv and kskv-table.csv.
The small tables needed for identifying the principal forms of nouns and verbs and the morphophonemic representations for the affixes can be browsed at GITHUB: kskn-affixes.csv and kskv-affixes.csv. Note that these files only cover those affixes that are present in the tables and they have no use after this stage. Full lists of affixes and their reprsentations are written later on.
Raw morphophonemes were calculated and the results are separate for nouns and verbs: kskn-raw.csv and kskv-raw.csv. You can browse them at GITHUB. Notice that the raw morphophonemes have longish names which will be shortened by renaming.
Rules were written one-by-one and tested right away. Note that this stage tries to handle all alternations by using morphophonemes and rules instead of continuation classes which would take care of different stems. The resulting set of rules can be seen in ksk-rules.twol.
The START and STOP directives were used when compiling in order to ignore those rules which have already been compiled and tested (just to speed up the test cycles). The writing of a rule consisted first of renaming the raw morphophoneme, see kskn-newnames.csv and kskv-newnames.csv. The example file needed by twol-comp was the concatenation of the renamed files for nouns and verbs, see ksk-examples.pstr
Once all rules seemed to be OK, the complete rule set was tested against the example file. In particular, now one could see what kinds of negative examples the rules would still accept. Some tuning of the rules was needed in order to get rid of obvious overgenerated forms. Some overgenerated forms actually were acceptable and lead to some additions in the example file rather than modifications to the rules.
From here on, the file containing the examples and the rule file became independent and the modifications were made directly to the examples rather than to the tables containing the inflected forms. Some phenomena were not present in the paradigm tables and needed examples which the tables would not accommodate.
8.8.6. Building KSKTWOL1¶
Nykysuomen sanakirja and Suomen kielen käänteissanakirja list 82 inflectional classes for nominals and 45 classes for verbs. Two files with patterns were created in order to map each headword together with its class number into its morphophonological representation which then served as a lexicon entry. The patterns are fairly loose and general at this stage as they have the inflectional class number available when deducing the morphophonemes. The patterns for nouns and adjectives is ofi-pat-na.csv and the one for verbs is ofi-pat-v.csv https://github.com/koskenni/ofitwol/blob/master/ofi/ofi-pat-v.csv. Using these pattern files and the program pat-proc-py lexical entries were produced using the two-level rules priviously written and tested. These entries corresponded to the noun, adjective and verb entries in the KSK. Those files are not published as it cannot be guaranteed that they are fully free from copyright.
The lexicon entries for lexemes need still inflectional affixes in order to make them a part of an operational morphological analyzer. The table listed the affixes and the information defining the combinations in which the affixes may occur. The affix file ofi-affixes.csv.
The table of inflectional affixes was so constructed that with some short Python scrpts, one could produce different versions of LEXC lexicons out of it. One version could analyze inflected word forms to their base form and grammatical features indicating the inflectional form. Another version produced the OFITWOL entry of the word instead of the base form. This was used in the stages for generating entries out of corpora.
8.8.7. Building OFITWOL1¶
The analyzer KSKTWOL1 was applied to a list word forms of The Finnish N-grams 1820-2000 of the Newspaper and Periodical Corpus of the National Library of Finland (http://urn.fi/urn:nbn:fi:lb-2014073038) published in Language Bank of Finland (Kielipankki, https://www.kielipankki.fi). The original list contained 243,398,561 distinct words. A subset of 122,170,884 words (klk-fi-1grams-lc.words) was made by including only words that consisted only of alphabetical characters and did not contain a hypehen at the beginning or at the end:
[a-zåäöšž][-a-zåäöšž']+[a-zåäöšž]
The smaller file contained still lots of words which were incorrectly recognized by the OCR progran, e.g.:
koaaerttimuallkkla
koaaerttipäivän
koaaerttlaaaallkkia
koaaet
koaaetaan
koaaeuteec
koaafamaan
Some of the underlying printed words could be guessed, eg. the first has probably been konserttimusiikkia but other instances are more difficult. For the current purposes, these noise words are not harmful at all. They are just ignored. One possible later uses of OFITWOL would be to improve the accuracy of the OCR of printed old Finnish texts.
Other sections of the list of word forms are analyzed with hfst-lookup using the KSKTWOL1 contain more useful information, e.g.:
aapeluskouluja aapeluskouluja+? inf
aapeluskukkoo aapeluskukkoo+? inf
aapeluslen aapeluslen+? inf
aapelusohjeena aapelusohjeena+? inf
aapelust aapelust+? inf
aapelusta aapelu{ØkØkk}s{ØeØeØ} /s;+N+SG+PTV 0,000000
aapelustaan aapelu{ØkØkk}s{ØeØeØ} /s;+N+SG+PTV+SG3 0,000000
aapelustakaan aapelu{ØkØkk}s{ØeØeØ} /s;+N+SG+PTV+KAAN 0,000000
aapelustani aapelu{ØkØkk}s{ØeØeØ} /s;+N+SG+PTV+SG1 0,000000
aapelustcn aapelustcn+? inf
aapelusten aapelu{ØkØkk}s{ØeØeØ} /s;+N+PL+GEN 0,000000
Here one can identify entries of the noun aapelus (aapinen, ‘alphabet book’) in five different forms. The other word forms shown are either misspellings or compound words of the same lexeme. Anyway, the analyzer shows that the word aapelus occurs in the corpus and that a lexicon entry aapelu{ØkØkk}s{ØeØeØ} /s; accounts for those five forms. The entry tells that the lexeme is inflected as aapelus, aapeluksen, aapelusta, aapeluksia. etc. Such lexicon noun, adjective and verb entries were taken as the initial lexicon of OFITWOL1 together with the affix lexicon.
The analysis produced some 1,3 million word forms with a noun entry, some 440,000 forms of an adjective entry, some 1.2 million forms of a verb entry, and some 7,500 forms of a particle (or adverb) entry.
The initial lexicon of OFITWOL1 was processed out of these results of the analysis programs and it contained 31,702 noun, 10,259 adjective, 15,472 verb and 15,472 particle (or adverb) entries.
8.8.8. Compound words¶
The overall plan is to include compound words as entries in the lexicon rather than just letting nouns follow other nouns freely. This allows more accurate recognition of compound words as compared to the free combination. The larger number of lexicon entries needed is not a problem for present day computers.
Compound word lexicon entries can be collected by using corpus. First, one collects analyzed word entries which are analyzed as SG NOM or as SG GEN. The analyzed corpus provided some 5,700 such candidates for first parts of compound words. A separate sublexicon was created for them and linked so that word forms could start with one of them and then continue with one of the noun entries.